Scentbird Analytics 2.0. Migrate from Redshift to Snowflake. Redesign ETL process.
As some of you may know I'm building analytics in Scentbird and my intial steps in building ETLs and choosing a data warehouse engine was not perfect. Initially, I'm a Java developer and I start that journey having zero experience in building data stack, I hope it gives me an excuse to commit some mistakes (by the way it is great that building analytics systems requires both skills and I have challenges like building micro-services at the time of creating another data pipeline).
Ok, let me show you what we had in our data stack and what issues did we met? Our data architecture at the beginning of 2019:
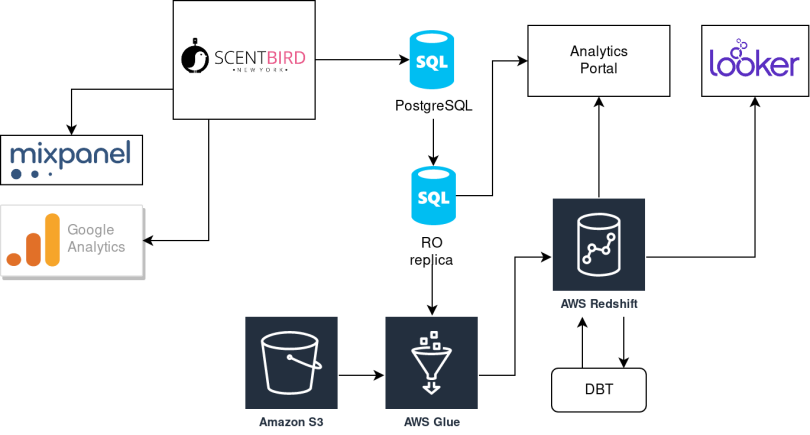
Some side notes regarding that schema:
- We have quite a classic ETL process based on AWS Glue jobs: extract data from Postgres Read-only replica, load it into a memory of Spark cluster, transform it and load to target warehouse.
- Once we discovered DBT tool, it appears the most of the transformations could be done at DBT, but we still unwrap JSON with GLUE jobs (due to Redshift limitations).
- We had a legacy self-build analytics portal. As Looker starts to cover all business needs, we were using it less and less.
It was built pretty straightforward to cover the basic need in analytics data. But since that moment we have dramatically increased in users (2020 pushed everyone online) and the amount of data we should collect. Moreover, we collect some issues of the current stack.
Redshift
Let start with the barebone of our stack - Redshift. What disadvantages did we collect?
- Computation power and storage space melted into one entity. It means you get a Redshift node with fixed storage amount and you have no opportunity to scale computation power without getting another full node with extra useless disk space and vice versa. We were using
DC2.largenodes with fixed 160Gb SDD storage space (the current price is ~$180 node per month). You have to deal with it until you become big enough to switch to nodesRA3.xlplusthat will cost you ~$800 node per month (and you will be required to buy at least 2 nodes to unlock the ability to manage storage amount separately from computation power). As the result, if you are spending less than $1600 per month you have to buy an additionalDC2node to extend your storage space or find out some way to unload your data to cold storage like Amazon Spectrum. In most cases we did not utilize the computation power of our cluster more than ~30-40%, however, our storage capacity was sitting above 85% all the time. In fact, we were buying disk storage space with huge overprice. - Scaling and cloning of fixed cluster is quite a slow operation. Redshift is doing a simple operation of copy in case of scaling or cloning your cluster. No tricks, except one: no downtime, just read-only mode. In case you'd like to add another
DC2node you will stay in read-only mode until a new cluster will be created and all data is copied there. In our case, it took almost 2 hours to scale the cluster. In case you are living with batch data processing, it is quite ok. What is more tricky - clone production data to staging cluster. Waiting for 2 hours until it will be complete... No, we have created some workaround. The full copy is done during non-working hours. In case you need to refresh the table during your development - run the script to dump and copy only the target table. It took less time, but it was still not suitable in the case of bi tables. - Hard to develop data models in parallel. Taking into account points #1 and #2 I'd say it was not so easy to develop new data models in parallel. Ideally, every developer should have his isolated data copy. In the case of redshift, it will increase your cost x times. To create one data copy per one developer you need space, but do you remember what it means? Yes, buy additional nodes to support space. Another option deal with limited dumps: it is really hard (we have almost 300 data models and the number of tables is quite the same) to create one according to your task and pull all the required tables. You have to create a special dump for every task and it is also not fun. The simplest way we found - use a shared dev environment. However, sometimes get extra issues during parallel development and debugging issues because of a clash with teammates.
- Poor ability to process JSONs. Redshift is really, really bad in terms of processing JSON documents. First of all, there are only a few JSON functions in Redshift, syntax is ugly. Secondly, JSONs process not so fast as you can expect. And the last one, Redshift not able to access all fields of JSON in case of tricky JSON objects with a bunch of internal arrays and objects. It could be a workaround by data preprocessing (as we do JSON unwrapping by AWS Glue), but in the current trend of moving from ETL to ELT it will be no popular solution.
AWS Glue
AWS Glue is allowed you easily create ETL jobs inside the Amazon ecosystem via UI. Back in 2017, it looks a good solution to start with. But let me focus on AWS Glue and the disadvantages we discovered later.
- Glue is the primary UI tool. Generated code is redundant repeats in every job you create. For sure you can generate most code via UI, but as result, you get something that looks like examples. Pretty complex for simple Extract and Load, but in case you have a couple of jobs it is ok. In our case we end up with 60+ jobs and creating code for every job via UI was not our way. To eliminate a lot of repeating code and put all jobs code in Git we create our wrapper around Glue SDK to shorten job code to minimal. As result, we get a job similar to:
from sbcommon import SBJob
sb_job = SBJob('SourceDatabaseName')
sb_job.extract_and_save("source_table", "target_table")
sb_job.finish()
- Glue is the primary UI tool once again. It is not easy to integrate jobs into your CI/CD process. To be able to automatically create new jobs from your code, amend an existing one, delete useless ones, update shared libraries you have to write your own code via AWS SDK. Once again we resolve it via our Python wrapper.
- Quite hard to develop/debug new jobs. There is no way to set up Glue locally or mock it somehow. You have to create a development instance of Glue in AWS Cloud and pay for it. You also have to mock all calls to Glue during your CI/CD tests just to test the code of your job so you get almost useless tests. Another point - no way to separate production and development environments. You can do it only by creating duplicated jobs attached to the test sources and target storage.
- Long warm-up time of Glue job. Glue job after start wait for AWS Cloud to allocate resources and startup Spark cluster. I have calculated the average warmup time for our production jobs during the whole history and it is ~7 minutes. In early 2021 AWS realized AWS Glue jobs v. 2.0 that promise warm-up time under 1 minute.
- Overwhelming calculation power of Spark cluster for simple Extract and Load operations. Every Glue job has Spark running under the hood and you can perform complex calculations with your data in memory in case you need it. All we were doing inside the Glue cluster, as mentioned before, was unwrap JSON documents because Redshift was not able to do it. To tell the truth, JSON appears in 8-10 of our Glue jobs. Rest 50+ was just simple Extract and Load, so we use a sledgehammer to hit small pins.
- It is tricky to do joins for late-arriving data/events. Processing arrived data is not only about joining (if any) with another source/table data arrived at the same time window. Sometimes you have to join a new delta with data that arrived yesterday or a week ago. You need to read and load it in memory of the Glue job before doing it. It could be a real time/memory/money consuming operation. Better just load raw data into target storage and perform all joins via DBT or any other tool. This fact makes Glue transformation useless in a lot of cases.
- Glue is not suitable for job orchestration. Glue provides you with triggers and you can create a workflow. It has very limited functionality. Not easy to integrate Glue workflow into your meta pipeline, where you have something to run after/before Glue workflow. Another issue you have to be very careful with the order of started jobs: job could not depend on successful completion of another job, it can be done only via triggers. You have to create a trigger that will start job B once job A completed. It means you have extra entity and extra chance to make something wrong. Resuming failed jobs (and the rest job going next) should be done manually and sometimes it is annoying.
8. Glue jobs often could be unstable due to Amazon internal issues. Couple times a month we get random job failed due to some strange issues (like no way to read data from S3 bucket). Most of them were recognized by AWS Support as internal issues and it was recommended just to rerun the job. Sometimes it means restart of the whole workflow and shifting the expected time of delivering data to business users.
External sources for ELT
Do you remember my initial architecture schema at the beginning of the article? Actually, it was changing rapidly starting in 2019. We started several subbrands, rework our application to a microservices-oriented way, adopted Snowplow, and have to include more and more external data obtained via API coming from Shopify, Facebook, Google Ads, and several more. We come to such architecture schema:
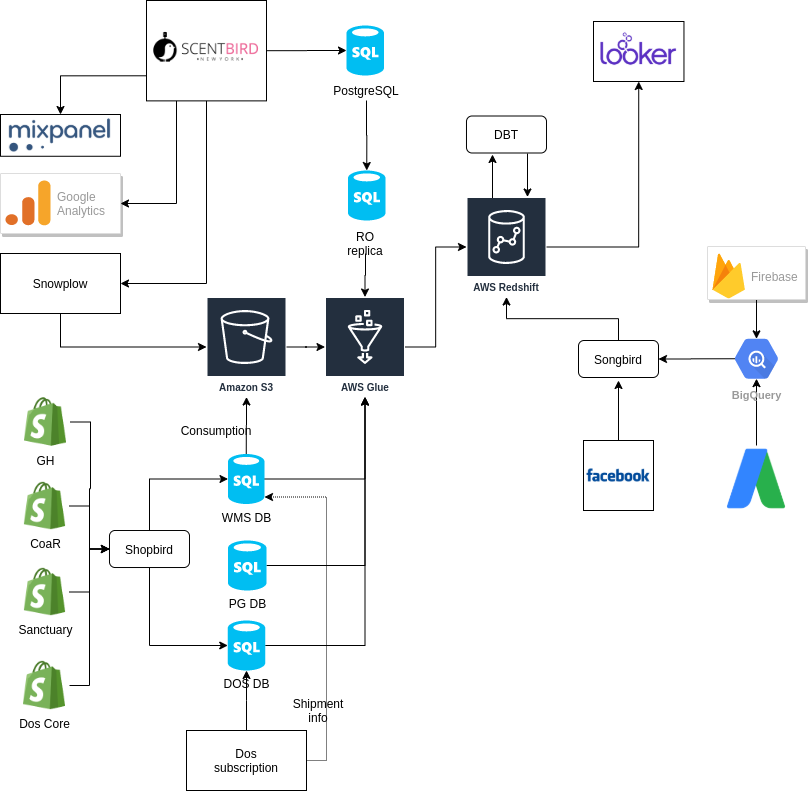
External APIs become a new challenge. We scanned for a possible solution and end up with Singer framework. We adopted it in our stack and works well for external API. It was a code-based tool, cheap in running, easily scaled, fast, and stable. It become obvious the most of AWS Glue functionality could be easily replaced in our stack, except for our needs in JSON data processors.
Snowflake
We have heard a lot about Snowflake and looks very sweet. Modern data warehouse with a lot of cool features compared to Redshift. We get an idea to perform some PoC with Snowflake: how good it is for our case? will it cost us more?
From the Snowflake team we get a demo:
- SQL syntax is 90% the same compared to Redshift;
- Computation power and storage space exist independently from a very beginning;
- Computation instances could be suspended automatically if there are no incoming requests;
- Autoscaling with zero downtime (or read-only mode);
- Zero copy clone of data: as data in snowflake are stored as a series of incremental changes, you can create your own data "branch" in a few minutes and it will require disk space only to store "pointers" to incremental you create your "branch" from;
- Time-travel feature allows you to get a snapshot of a table at any moment back up to 90 days. It means you can stop doing everyday backup until your retention policy is below 90 days;
- Undo of drop operation (table/schema);
- JSON-friendly: great JSON support, auto-formatting of stored JSON data;
- Snowflake was compatible with any tool in our stack except AWS Glue;
We want to go further, but we couldn't do it because of AWS Glue: it could not be connected to Snowflake without undocumented tricks. We decided to give a try to Singer act as the main pipeline framework on delivering data to Snowflake during PoC.
Singer
As we already were running singer as our ETL tools for external sources it was quite easy to adapt it to transfer data from our internal databases (a lot of Postgres databases) to the data warehouse. We decided to compare its results with the same sources and targets vs. AWS Glue. We took 3 tables with our average amount of rows per table, 2x average number of rows and a table with really few rows to make us fall overhead of Glue for small tables.
| Table | Glue warm up time + ETL time (avg over 70 runs) | Singer time (warm + ETL) (avg over 70 runs) |
|---|---|---|
| Table_A (12M rows) | 6.1 minutes + 4 minutes | Total time for 3 tables: 8.85 minutes |
| Table_B (6M rows) | 20 seconds + 4.9 mintues | |
| Table_C (58 rows) | 30 seconds + 1 mintutes | |
| Total | ~7 minutes + ~10 minutes | 8.85 minutes |
You could notice some AWS Glue jobs (Table_B and Table_C) has short warm-up time. I suspect they somehow assigned to already warmed up by Table_A job instances (All jobs was running in a chain Table_A->Table_B->Table_C). Singer is much more efficient (almost 2x times faster). Even if compare only pure time for moving data, Singer is doing it more efficient (8.85 minutes vs 10 minutes). Additionally, we have found a great wrapper over Singer most popular taps Pipelinewise that makes installation and configuration of Singer framework much easier. So we decided we are ready to go to ELT process fully build over Singer.
Snowflake PoC
Once we get a working pipeline connected to Snowflake we are ready to build PoC (proof of concept). Plan for building it:
- Pickup couple of the most complex data models in DBT and get the list of tables involved in building those models;
- Dump historical data from Redshift to Snowflake for picked up tables;
- Setup singer as ETL tools to move everyday delta from source to Snowflake for picked up tables;
- Convert chosen DBT data models from Redshift SQL to Snowflake SQL;
- Compare results for the building data model and executing complex SQLs from Looker;
We managed to build PoC and run tests quite fast and get data produced 4 times faster with Snowflake's instance Small (it should be equal to Redshift's DC2.Large in price) and 6 times faster with Medium type of Snowflake instances (just to be sure additional money save us some time in future).
Job orchestration. Argo PoC
So far so good. We were almost ready to switch to Snowflake + Singer instead of Redshift + Glue. But we are missing one part - job triggers and orchestrations. Glue was doing the orchestration of our jobs. Not so good as we'd like it to do, but we had such ability. Singer does not provide any built-in tool for running jobs in a proper way and at a proper time. Once I've been visiting Data Counsil conference in 2019 I faced an interesting DAG tool: Argo Workflow. And looks like it suits us well, because of our switch to Kubernetes. We gave it chance as another tool in our data stack. And it works perfectly:
- every job in workflow runs in a separate Kubernetes pod, so it is isolated, resource efficient and easy restartable;
- every job is a Docker container, so it means you can have packed any technology inside;
- it is really easy to build DAG using your job configurations;
- workflow could be started by classic cron triggers or via API call;
- Argo has a really tiny and fast UI;
We decided to covert our jobs to Argo jobs in such way:
- Every combination of singer tap and target is packed in a separate Docker image.
- Every source of data gets its own Argo job based on proper Singer Docker image and is provided with custom resource settings of Pod (you can tune CPU and memory consumption depending of a number of rows you need to transfer). In this case, you also get the ability to resync a particular data source in one click via Argo.
- In case we have a lot of tables to transfer in one source, we create several Argo jobs based on the same Docker image, but pass a different list of tables to sync. It gives an ability to extract data from the same source in parallel via several Argo jobs. In case of any issue with Argo job you have to resync only part of tables and not all of them, that could be expensive in case there are hundreds of tables packed in one job.
- We have created a special Docker image to run DBT after all data migration is completed.
- All Argo jobs are linked in one big workflow that starts once a day by cron trigger. So we have such a logical schema:
Cron Trigger->ETL Jobs->DBT Job->Slack Notification Job.
As result our Argo workflow:
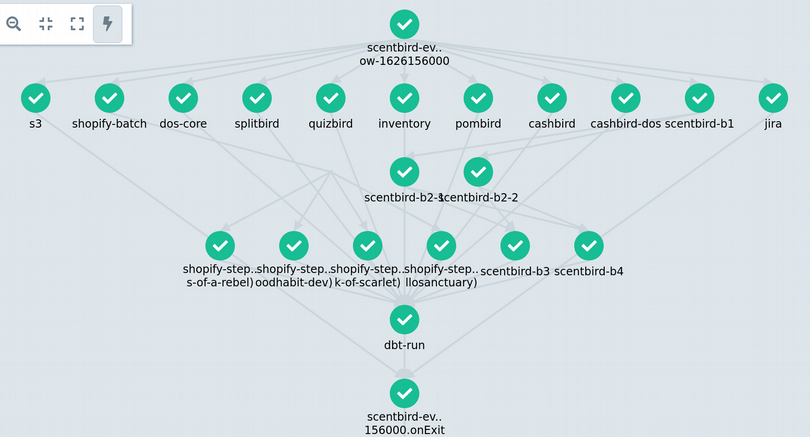
You can explore and reuse our template for Argo+Singer ETL here.
Migration itself
Ok, we had to do several proofs of concepts, research different tools, and find out a new solution to organize our ETL pipeline. The next step is migration itself. We came up with such a plan:
- Create a role model in snowflake, create users for every tool we use.
- Setup Argo and Singer to move data in Snowflake from internal databases in parallel to Redshift.
- Setup Singer to move data in parallel into Snowflake from external sources (GA, Facebook, Shopify, etc.).
- Dump Redshift historical data and put it into Snowflake, start Singer running to make everyday data update to Snowflake.
- Convert all DBT models to Snowflake SQL in a separate branch and set up regular DBT build in Snowflake from the branch.
- Compare data in Redshift and Snowflake arriving in parallel (should be no diffs in numbers). We need to run both databases for one month to have the ability to check several end-of-month reports.
- Switch off Glue jobs, stop Redshift collecting backups, stop DBT running for Redshift.
- After some retention period (2-3 weeks) stop Redshift instances. Save the latest backup.
Our initial ETA was to complete migration in 3 months, however, it took us almost 5 months. For sure there were some hidden issues we have to face with and it took additional time to work around them. About couple of them I created separate posts (here and here).
In the end
We are running Snowflake, Argo, Singer, DBT stack for 6 months already. Our current architecture schema:
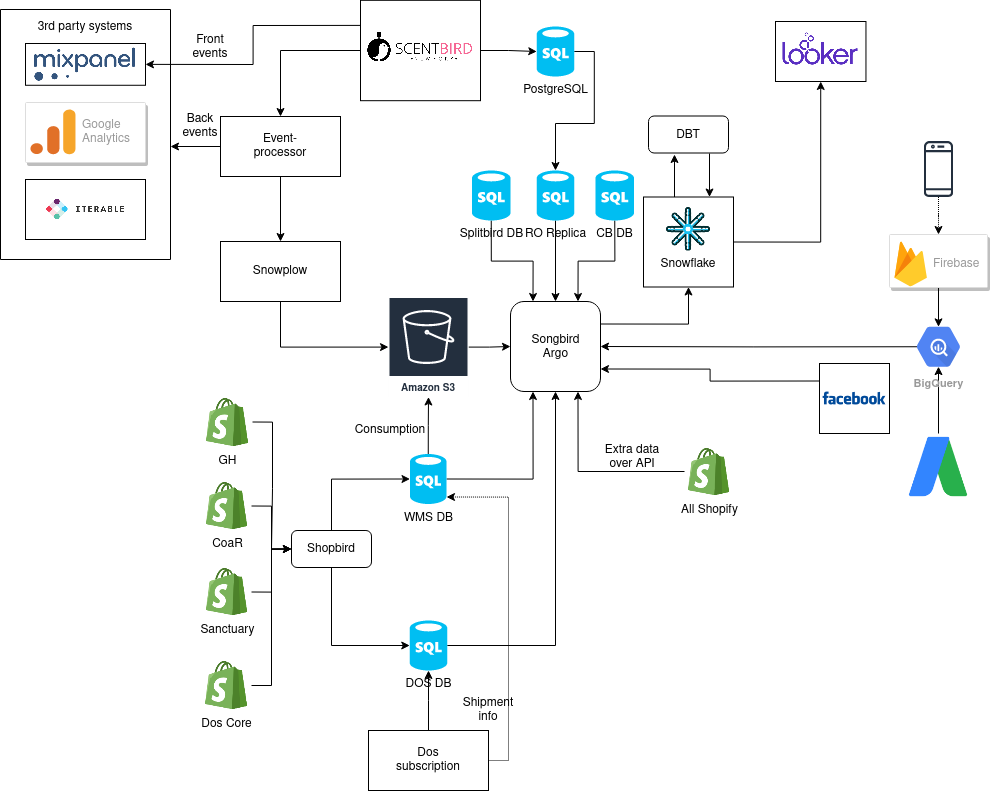
Why this type of architecture is better:
- Using the only EL (Extract and Load) tool for all types of data sources (Singer).
- Ability to scale in any component independently. Decoupled storage and computing power (Snowflake).
- The whole EL + T process now takes 1.5 hours instead of 3-3.5 hours based on Aws Glue and Redshift. And it could be cut down to 1 hour for additional money (using medium instances instead of small in Snowflake), but there is no need for us to spend additional money to get an extra half an hour in the night.
- Reduce cost 50% for the whole stack (Singer+Argo cost almost nothing compared to Aws Glue). Snowflake reduced our cost dramatically thanks to the ability to suspend not used instances.
- Improve stability of the whole EL process (there is no more failed EL jobs because of EL engine itself).
- Durability of Argo+Singer solution is great. Zero effort to maintain those solutions.